



Authors: Nikhil Shivakumar Nayak, Krishnateja Killamsetty, Ligong Han, Abhishek Bhandwaldar, Prateek Chanda, Kai Xu, Hao Wang, Aldo Pareja, Oleg Silkin, Mustafa Eyceoz, Akash Srivastava
Visualizing Our Method
Below is a visual summary from our paper that illustrates our continual learning approach at a high level:
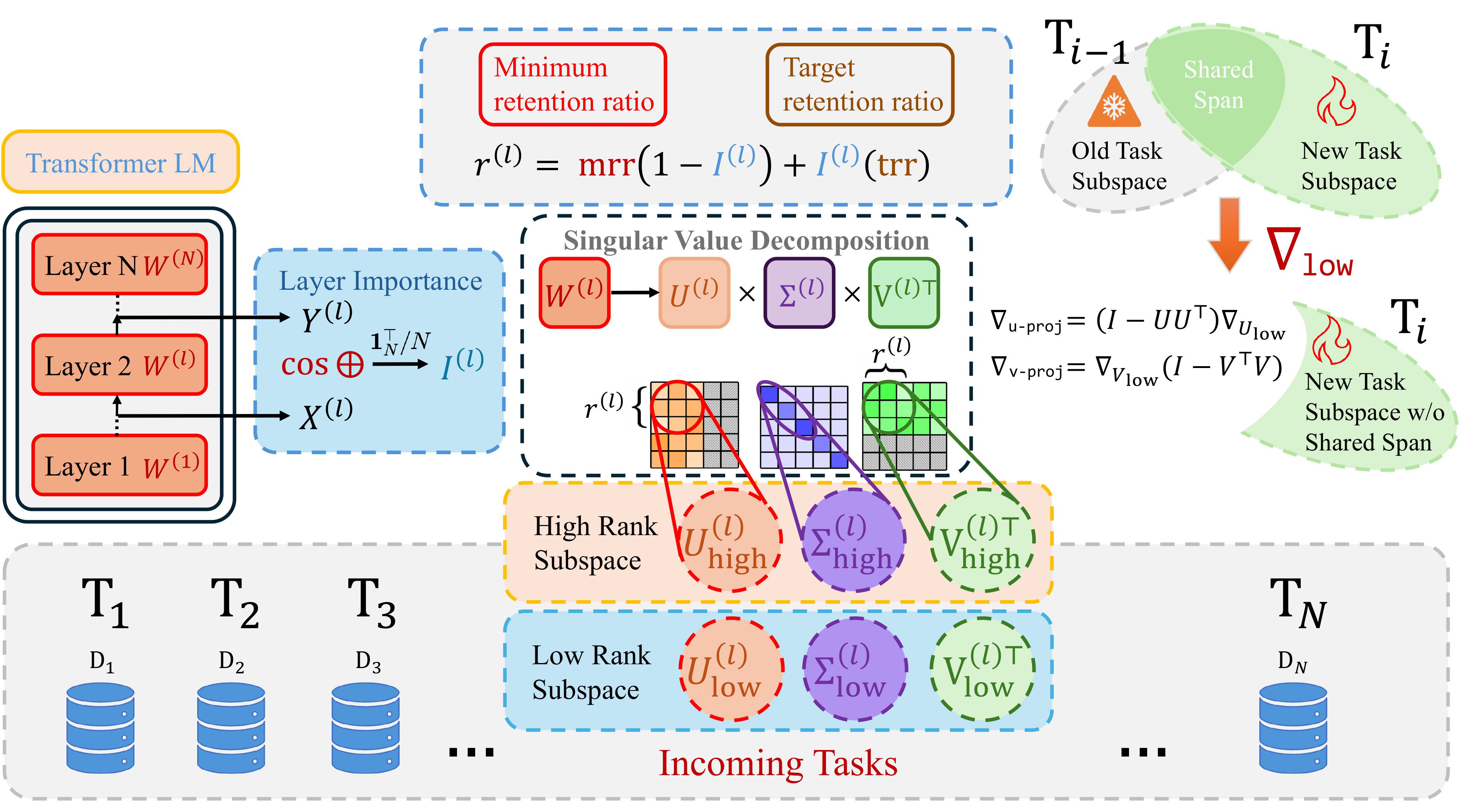
Figure: Our adaptive SVD method dynamically separates each weight matrix into high-rank (critical) and low-rank (safe-to-update) subspaces. Updates occur exclusively within low-rank directions orthogonal to crucial knowledge.
Introduction: The Challenge of Post-Training Large Language Models (LLMs)
In recent years, Large Language Models (LLMs) like GPT-4, Gemini 2.5, and Claude 3 have revolutionized artificial intelligence, demonstrating astonishing capabilities across an expansive range of tasks—from answering complex queries and generating coherent narratives, to assisting programmers and solving intricate mathematical problems. These models, trained on massive datasets and billions of parameters, have quickly become indispensable tools in academia and industry alike, showcasing the transformative potential of modern AI systems.
However, despite their remarkable capabilities, the practical deployment of LLMs in enterprise environments exposes a critical and yet often overlooked challenge: continual adaptation. Unlike static benchmarks or academic experiments, real-world scenarios are fluid, dynamic, and ever-evolving. In enterprises, fresh data streams in continuously, new products are introduced daily, user preferences evolve rapidly, and regulations or compliance requirements frequently change. For instance, consider a customer-service chatbot at a large tech firm: new products or policies require the model to quickly update its internal knowledge. In practice, this means large language models must constantly update their knowledge and acquire new skills without forgetting previously learned information. Retraining these enormous models from scratch with each new task or data stream is computationally infeasible, both financially and environmentally, due to the enormous computational resources and energy required. Alternatively, maintaining separate specialized models for every new task or data subset quickly becomes impractical, as it leads to prohibitive maintenance complexity and cost.
This essential capability—the ability of a model to continually learn and adapt to new information is known in machine learning literature as continual learning. Unfortunately, large language models are notoriously prone to a phenomenon called catastrophic forgetting: when models are updated or fine-tuned on new tasks or data, they frequently overwrite or interfere with previously learned knowledge. The result is a severe performance degradation on tasks the model previously excelled at, essentially “forgetting” what it once knew.
Given these practical challenges, continual learning is now arguably the most crucial bottleneck in leveraging large language models effectively in real-world, high-stakes applications. Addressing catastrophic forgetting in large-scale neural networks isn’t just an academic exercise—it’s a fundamental requirement for the deployment and maintenance of scalable, reliable, and continuously improving AI systems.
In this blog post, we describe a recent breakthrough we developed to address this very challenge: a novel, theoretically-grounded method that enables continual fine-tuning of large language models with near negligible levels of catastrophic forgetting, while fully leveraging the model’s expressive capacity. Unlike current approaches that freeze large parts of the model or add task-specific modules, our solution elegantly repurposes the internal capacity of the model itself, effectively learning new tasks without sacrificing previously acquired knowledge.
We call our method “Sculpting Subspaces”—because it selectively reshapes and refines the model’s internal parameter space, carving out unused regions for new tasks, all the while carefully preserving essential prior knowledge. In the following sections, we’ll dive deeper into the concept of catastrophic forgetting, explore the limitations of existing solutions, and then fully unveil how our adaptive singular value decomposition (SVD)-based approach can radically transform the way we think about continual learning and enterprise-scale deployment of large language models.
The Elephant in the Room: Catastrophic Forgetting
Imagine you’re training an intelligent assistant to handle customer support at your company. Initially, the assistant learns everything about your current products and customer needs. It performs brilliantly—answering questions, handling complaints, and providing clear solutions. A few months later, your company launches a new product line. Naturally, you update your assistant to understand and support these new products. But then something surprising and frustrating happens: suddenly, the assistant struggles to answer basic questions about your older products—questions it previously answered flawlessly.
This phenomenon isn’t hypothetical; it’s a well-known, pervasive problem in machine learning called “catastrophic forgetting.” At its core, catastrophic forgetting occurs when a neural network is updated to learn a new task or incorporate new data, and in the process, it inadvertently erases or significantly damages knowledge it previously acquired. Neural networks, especially the enormous transformer-based architectures powering today’s most powerful LLMs, represent knowledge through distributed connections between millions—or even billions—of parameters. When these connections are updated to accommodate new information, the precise tuning that previously enabled high performance on older tasks often gets disrupted. For example:
-
Enterprise Knowledge Management: Companies regularly update policies, introduce new products, or retire old services. Each update risks impairing a language model’s ability to retrieve or utilize previously learned knowledge crucial to ongoing customer interactions or internal operations.
-
Medical Applications: Consider a healthcare-focused language model that assists clinicians by providing diagnostic guidance or referencing up-to-date treatment protocols. If updating the model with the latest medical research causes it to “forget” critical older knowledge—like standard drug interactions or established clinical procedures—the consequences could be severe and potentially dangerous.
The issue is further magnified by the fact that in practical scenarios, updates aren’t occasional—they’re frequent and continuous. Enterprises experience a near-constant influx of data, shifting customer expectations, and evolving business strategies. If every incremental update to the language model leads to catastrophic forgetting, the model quickly becomes unreliable and potentially unusable, resulting in lost trust, increased operational costs, and significant frustration among users and stakeholders.
Thus, catastrophic forgetting is not just a theoretical curiosity—it’s a profound challenge that urgently demands robust solutions. If large language models are to realize their full potential in the real world, we must equip them with the capability to continuously learn, update, and adapt—without losing their accumulated knowledge.
Why Existing Solutions Fall Short
So, catastrophic forgetting is clearly a significant obstacle. Naturally, the machine learning community has proposed various solutions to tackle it. Unfortunately, most existing approaches come with notable limitations and fail to fully address this challenge in practice. Let’s break them down one by one.
Replay Buffers: Why Revisiting Old Data Isn’t Enough
One common workaround to mitigate forgetting is the use of replay buffers—storing and periodically revisiting examples from previously learned tasks during training of new tasks. The idea here is intuitive: if the model regularly revisits older data, it should, in theory, retain previously learned information.
However, while replay buffers help to some extent, they introduce several practical and fundamental issues:
-
Performance Still Degrades:
Even with replay, performance gradually drops as the number of tasks increases. The buffer size is typically limited due to memory constraints, meaning older tasks inevitably get underrepresented over time, causing slow and steady forgetting. -
Data Availability Constraints:
In enterprise settings, it’s often simply not possible to retain previous task data indefinitely. Licensing agreements, strict privacy regulations (such as GDPR or HIPAA), and proprietary data ownership rules can prohibit continuous storage or reuse of past training data. -
Impracticality for Large Models:
For large language models trained on massive, web-scale datasets (e.g., GPT-4, LLaMA-2), maintaining even a small representative buffer is typically infeasible or impossible—both due to data privacy issues and the sheer storage size required.
So, while replay buffers seem promising at first glance, they’re hardly a silver bullet. In many realistic deployments, especially involving LLMs, replay buffers simply aren’t a practical solution.
Parameter-Efficient Methods (Adapters, LoRA): Efficient but Constrained
To avoid replay altogether, researchers have turned towards methods that freeze most of the pretrained model parameters and only update small task-specific subsets. Popular methods in this category include Adapters and Low-Rank Adaptation (LoRA). The intuition here is clear: by limiting parameter updates to a tiny fraction of the model, interference with previously learned knowledge should be minimized.
However, despite their efficiency, these methods have serious limitations:
-
Limited Model Expressivity:
By freezing the vast majority of model parameters, you’re essentially forcing your model to learn new tasks within a very narrow parameter space. Imagine trying to repaint your house using only one small brush—you’ll quickly run out of flexibility, and the result won’t look great. -
Scalability Issues:
Every new task adds new parameters—small adapters or LoRA modules. Over time, these additional parameters pile up, increasing memory usage and inference complexity, gradually undermining the original promise of efficiency. -
Performance Ceiling:
Because updates occur only in restricted subspaces, models struggle to achieve top-tier performance on tasks that differ significantly from previous ones, especially over long sequences of tasks. Eventually, this limited flexibility can severely constrain the overall capability of the model.
So yes, LoRA might be efficient. But let’s be blunt—if your goal is to maintain state-of-the-art performance in continuously evolving tasks, it’s ultimately a waste of your valuable time (😜).
Model Merging Methods (SLERP, TIES): Powerful but Impractical
Another creative line of solutions involves model merging methods—approaches like SLERP (Spherical Linear Interpolation) or TIES (Task-Informed Ensemble Synthesis). These methods train separate models or adapters for each task and later combine (or merge) their parameters into a unified model.
Though conceptually elegant, these techniques quickly run into their own set of problems:
-
High Computational Overhead:
Training multiple separate models or adapters—and then merging them—requires massive computational resources. This cost escalates quickly as the number of tasks increases. -
Complexity and Expertise Required:
Merging model parameters isn’t straightforward; it demands careful tuning, hyperparameter optimization, and expert judgment. Without this, merged models often perform significantly worse than individually trained models. -
Suboptimal Performance:
Even after extensive tuning, model merging typically achieves lower performance than training a single model simultaneously on all tasks (multitask learning). Achieving good results consistently requires a prohibitive amount of experimentation and fine-tuning.
For real-world enterprise deployments, this complexity makes model merging largely impractical. You need something simpler, more efficient, and easier to maintain. Given these limitations, we clearly need a fresh perspective—one that offers a fundamentally new approach to continual learning. And that’s exactly what we’ll introduce next.
Sculpting Subspaces: A Novel Solution Using Adaptive SVD
This brings us to our paper’s approach, which we fondly call “Sculpting Subspaces.” To understand this intuitively, imagine you’re an artist sculpting a statue from a block of marble. The statue you carve represents the critical knowledge your model has acquired. Now, when new tasks arrive, rather than recklessly reshaping your sculpture (which could damage its existing features), you carefully carve into unused or less important parts of the marble. You reshape the edges, refine the details—but crucially, you leave the core sculpture intact.
That’s precisely how our method works. We leverage Singular Value Decomposition (SVD)—a powerful mathematical tool that decomposes matrices into simpler, interpretable parts—to identify which parts of the model’s internal “marble” (parameters) can safely be updated, and which parts encode critical knowledge that must be preserved.
Why SVD? An Intuition
Neural network parameters, particularly in large language models (LLMs), often contain substantial redundancy. Recent research confirms that many directions (combinations of parameters) within these networks don’t meaningfully impact the model’s performance—they essentially represent unused capacity or “noise” (Sharma et al., 2023, Hartford et al., 2024). SVD lets us mathematically identify these unused directions by decomposing a weight matrix ($\mathbf{W}$) into simpler components:
\[\mathbf{W} = \mathbf{U} \Sigma \mathbf{V}^\top\]Here:
- $\mathbf{U}$ and $\mathbf{V}$ represent sets of orthogonal directions (vectors).
- $\Sigma$ is a diagonal matrix containing singular values that tell us how important each direction is. Large singular values indicate important directions (“high-rank”) that encode critical knowledge, while small singular values indicate less important, redundant directions (“low-rank”).
By clearly identifying these directions, we can “sculpt” our parameter updates strategically:
- High-rank directions (large singular values): Preserve these, since they’re crucial for retaining previously learned tasks.
- Low-rank directions (small singular values): Safely update these directions to learn new tasks, since they don’t significantly impact previous knowledge.
This intuitive approach elegantly balances knowledge retention (stability) with flexibility for learning new information (plasticity)—exactly what’s needed for continual learning.
Under the Hood: How Adaptive SVD Enables Continual Learning
Now, let’s dive a little deeper into how exactly our adaptive SVD method works, step-by-step:
1. Dynamically Identifying High- and Low-Rank Subspaces
For each task, we first perform a quick Singular Value Decomposition (SVD) on each weight matrix in our model (for example, attention and feedforward layers in LLaMA-2):
\[\mathbf{W}^{(l)} = \mathbf{U}^{(l)} \Sigma^{(l)} (\mathbf{V}^{(l)})^\top\]We sort singular values in descending order. This separates directions into two intuitive categories:
- High-rank subspace: Directions with large singular values, encoding critical knowledge from prior tasks.
- Low-rank subspace: Directions with small singular values, representing unused model capacity or redundant parameters.
2. Determining Layer Importance through Input–Output Similarity
But not all layers are created equal. Some layers predominantly pass information through the model, while others significantly transform it. Inspired by AdaSVD, we calculate the importance of each layer dynamically by measuring how much a layer transforms its input to output activations:
\[I^{(l)} = \frac{1}{N} \sum_{i=1}^{N} \text{cosine_similarity}\bigl(\mathbf{X}_i^{(l)}, \mathbf{Y}_i^{(l)}\bigr)\]- If inputs and outputs are highly similar, this layer mostly preserves information and thus should retain more singular vectors.
- If they’re dissimilar, it may indicate that the layer squashes input in certain directions effectively making it low-rank, so these directions can be repurposed for learning new tasks.
We normalize these importance scores across layers to prioritize parameter updates strategically.
3. Adaptive Rank Selection Based on Layer Importance
Instead of arbitrarily choosing how many singular vectors to preserve, we use layer importance scores to adaptively determine how much “marble” (parameters) we must preserve:
\[r^{(l)} = \mathrm{mrr} + I^{(l)}(\mathrm{trr} - \mathrm{mrr})\]Here:
- Minimum Retention Ratio (mrr) and Target Retention Ratio (trr) are hyperparameters (set to 0.1 and 0.8 respectively based on empirical observations) that control how aggressively we update parameters.
- More important layers (high $I^{(l)}$) retain more singular vectors, ensuring stability for crucial knowledge. Less important layers safely update more aggressively, efficiently adapting to new tasks.
4. Ensuring Orthogonal Updates: Protecting Crucial Knowledge
Finally, when updating model parameters, we ensure that updates remain completely orthogonal (at right angles) to the high-rank subspace. This crucial step prevents accidental overwriting of important previous knowledge:
\[\nabla \mathbf{W}^{(l)}_{\mathrm{proj}} = \nabla \mathbf{W}^{(l)} - \mathbf{U}^{(l)}_{\text{high}}(\mathbf{U}^{(l)}_{\text{high}})^\top \nabla \mathbf{W}^{(l)} \mathbf{V}^{(l)}_{\text{high}}(\mathbf{V}^{(l)}_{\text{high}})^\top\]By projecting gradients this way, we guarantee that every update for a new task is safely confined to the unused low-rank subspace, leaving the model’s previous knowledge intact. Leveraging the internal geometry of LLM parameters, we efficiently balance stability and adaptability, opening the door for genuinely lifelong learning in real-world deployments.
Results that Speak for Themselves: Empirical Evaluation 🚀
Great theories and clever methods are exciting—but at the end of the day, what matters most are results. Can our adaptive SVD-based approach truly solve catastrophic forgetting? Can it outperform state-of-the-art solutions like O-LoRA? Let’s find out!
To answer these questions thoroughly, we evaluated our method on two distinct sets of benchmarks:
- Standard Continual Learning (CL) benchmarks: Consisting of multiple sequential classification tasks (like AG News, Amazon Reviews, DBpedia, and more).
- TRACE benchmark: A more challenging real-world scenario involving instruction-following and complex reasoning tasks.
Let’s explore the results step by step.
🧑🔬 Standard Continual Learning (CL) Benchmarks
We first evaluated our method on two widely-used CL benchmarks:
- Standard 5-task Benchmark (AG News, Amazon Reviews, Yelp Reviews, DBpedia, Yahoo Answers)
- Extended 15-task Benchmark (combining classification tasks from GLUE, SuperGLUE, IMDB, and the original 5-task dataset)
We compared our method against multiple baseline techniques, including:
- SeqFT: Naive sequential full-model fine-tuning (prone to severe forgetting).
- Replay buffers: Revisiting old data to prevent forgetting.
- LoRA-based methods (SeqLoRA, IncLoRA, and state-of-the-art O-LoRA).
- Regularization methods (EWC, LwF).
- Prompt-based methods (L2P, ProgPrompt).
- Multi-task learning (MTL): Ideal upper-bound trained simultaneously on all tasks.
Here’s how our Adaptive SVD method stacks up:
🎯 Performance on Standard CL Benchmarks (T5-Large Model)
| Method | 5-task Accuracy (%) | 15-task Accuracy (%) |
|---|---|---|
| SeqFT | 28.5 | 7.4 |
| SeqLoRA | 43.7 | 1.6 |
| IncLoRA | 66.4 | 61.2 |
| Replay | 57.8 | 54.2 |
| EWC | 48.7 | 45.1 |
| LwF | 52.3 | 46.9 |
| L2P | 60.7 | 56.1 |
| LFPT5 | 72.7 | 69.2 |
| O-LoRA (Previous SOTA ⭐️) | 75.8 | 69.6 |
| Ours (Adaptive SVD) 🚀 | 75.9 | 71.3 |
Key Insights:
- On the challenging 15-task scenario, our method outperforms state-of-the-art O-LoRA (71.3% vs. 69.6%).
- For the standard 5-task scenario, our approach achieves slightly better accuracy (75.9% vs. 75.8%), highlighting its stability even with fewer tasks.
- Our approach clearly surpasses traditional replay buffers, naive fine-tuning (SeqFT), and parameter-efficient methods, demonstrating robust knowledge retention without catastrophic forgetting.
TRACE Benchmark: Real-World, Complex Tasks
The TRACE benchmark presents a realistic and challenging scenario designed explicitly to test continual learning methods on instruction-following and reasoning tasks. Here, we used the LLaMA-2-7B-Chat model, evaluating our method on diverse tasks covering multilingual comprehension, arithmetic reasoning, coding, and more.
TRACE Benchmark Performance (LLaMA-2-7B-Chat)
| Method | Average Accuracy (%) | Backward Transfer (%) |
|---|---|---|
| SeqFT | 23.0 | -8.3 (Forgetting ❌) |
| O-LoRA (Previous SOTA ⭐️) | 41.3 | 6.2 |
| Ours (Adaptive SVD) 🚀 | 48.4 | 7.1 |
| PerTaskFT (Ideal baseline) | 57.6 | N/A |
| MTL (Upper bound) | 52.3 | N/A |
Key Insights:
- Our adaptive SVD approach achieved 48.4% average accuracy, clearly surpassing O-LoRA (41.3%)—a substantial margin indicating significantly reduced catastrophic forgetting. (Average accuracy is computed across all tasks after the final task has been learned in sequence.)
- Remarkably, we achieved the best backward transfer (7.1%), meaning our method not only maintains previous knowledge but sometimes even slightly improves earlier tasks—a key marker of successful continual learning. (Backward transfer measures the difference between accuracy on a task after the final task is learned and its accuracy immediately after it was first learned.)*
General Ability Across Core Capabilities
One critical requirement for real-world enterprise deployment is that models preserve their general linguistic and reasoning abilities even after continual updates. This includes a broad set of capabilities such as factual knowledge, general and commonsense reasoning, reading comprehension, and multilingual understanding. To evaluate this, we use a set of diverse benchmarks covering key dimensions from TRACE:
- Factual Knowledge (MMLU)
- General Reasoning (BBH)
- Commonsense Reasoning (PIQA)
- Reading Comprehension (BoolQA)
- Multilingual Understanding (TyDiQA)
- Math Reasoning (GSM)
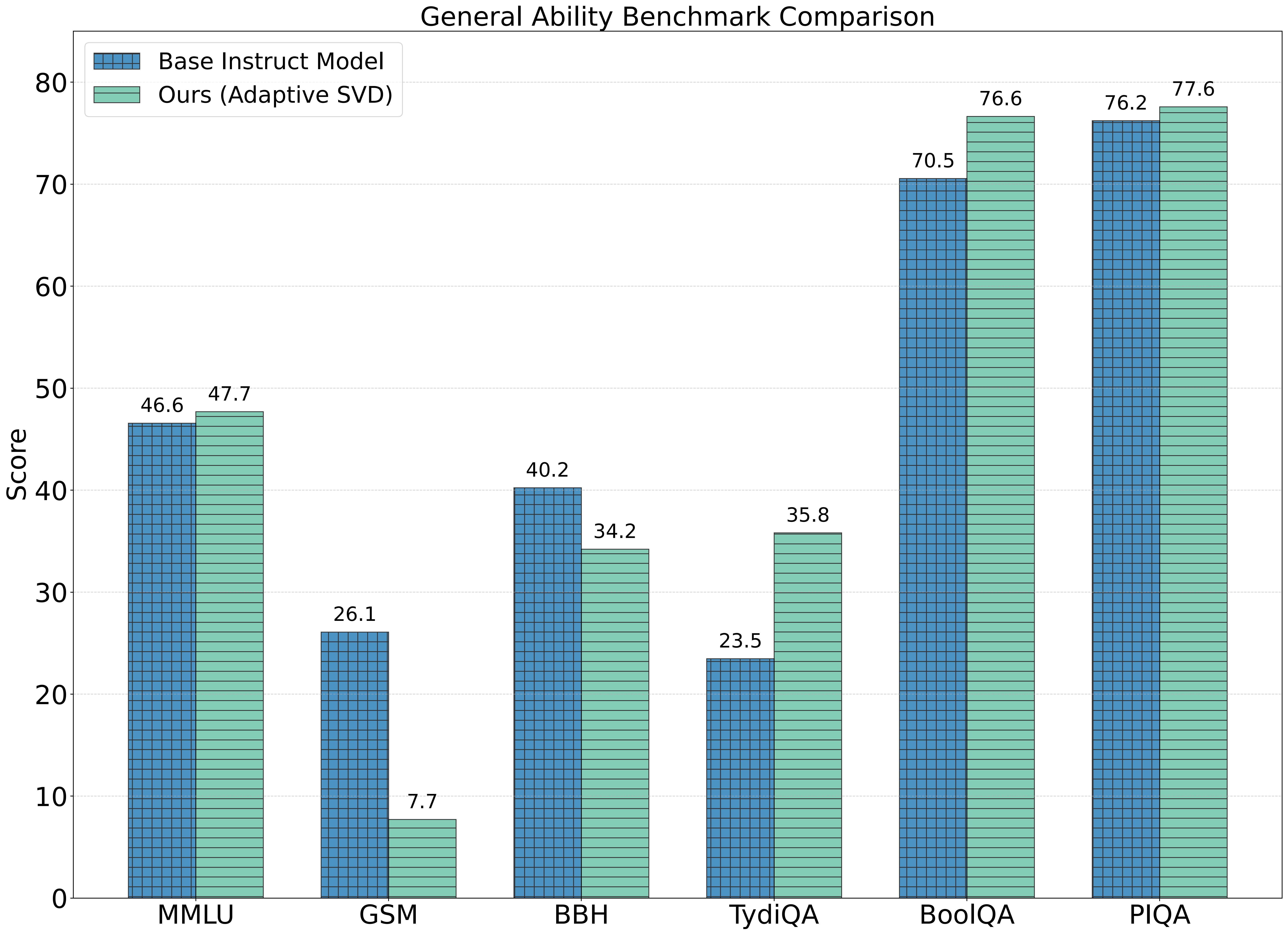
Figure: General ability evaluation across six core dimensions—factual knowledge (MMLU), general reasoning (BBH), commonsense reasoning (PIQA), reading comprehension (BoolQA), multilingual understanding (TyDiQA), and math reasoning (GSM).
Our method effectively preserves or even improves performance across most general ability tasks, with particularly strong gains in multilinguality, reading comprehension, and commonsense reasoning. The modest drop in arithmetic and general reasoning is likely due to these tasks’ reliance on longer, multi-step computation paths, which are more sensitive to fine-tuning.
🛡️ Preservation of Instruction-Following and Safety
We also evaluated instruction-following and safety, comparing our approach directly against the original LLaMA-2-7B-chat model:
| Method | Instruction-Following (Win/Tie/Lose %) | Safety (Win/Tie/Lose %) |
|---|---|---|
| Replay | 10 / 18 / 72 | 0 / 88 / 12 |
| LoRASeqFT | 3 / 4 / 94 | 0 / 86 / 14 |
| SeqFT | 14 / 34 / 53 | 0 / 98 / 2 |
| Ours (Adaptive SVD) 🚀 | 24 / 56 / 20 | 18 / 78 / 4 |
Our method significantly outperforms all other continual learning baselines in retaining both instruction-following abilities and model safety, crucial for maintaining trust and reliability in real-world deployments.
Summarizing the Impact
In short, these extensive evaluations clearly demonstrate that our Adaptive SVD method is more than just a novel theoretical idea—it represents a meaningful, practical breakthrough in continual learning:
- Outperforms the previous state-of-the-art (O-LoRA) on diverse continual learning benchmarks.
- Dramatically reduces catastrophic forgetting, ensuring stable, lifelong learning.
- Maintains general linguistic capabilities, safety, and instruction-following, essential properties for practical enterprise adoption.
🚀 Why Enterprises Should Care: Real-World Impact
At the end of the day, technology only matters if it genuinely solves real-world problems—especially in enterprise environments. So, why should enterprises care about our Adaptive SVD approach?
1. Seamless Continual Adaptation
In the real world, new data, tasks, products, and policies arrive almost daily. With our method, large language models can now continuously adapt to this stream of changes—without sacrificing previous knowledge. Enterprises no longer have to choose between constant retraining or risking outdated models. Instead, you get a single, stable, continuously learning model.
2. Massive Infrastructure Savings
Today, companies often deploy separate specialized models or expensive ensembles for different tasks or departments. This approach quickly becomes unsustainable. Our Adaptive SVD solution significantly reduces costs by enabling a single adaptable model to handle multiple tasks seamlessly, dramatically cutting storage requirements, computational resources, and maintenance overhead.
3. Trustworthy and Reliable Deployments
Beyond raw performance, enterprises must ensure their models are safe, trustworthy, and reliably follow instructions. Our method explicitly preserves general linguistic capabilities, safety, and instruction-following accuracy. This is a massive win, helping enterprises maintain customer trust, comply with safety standards, and ensure consistent, reliable interactions.
In short, our approach transforms continual learning from a theoretical concept into a practical, scalable solution—perfectly suited for the fast-paced, constantly evolving demands of modern enterprise environments.
Limitations and Exciting Future Directions
Of course, no method is perfect. While our Adaptive SVD approach is highly effective, we want to transparently discuss a few important limitations and highlight opportunities for future improvement:
-
Rank Estimation Sensitivity:
Our approach depends significantly on correctly estimating the optimal “rank”—the balance between preserving knowledge and learning new tasks. Inaccurate estimates can degrade performance. Future research will explore more robust, theoretically grounded ways to automatically and dynamically estimate effective ranks. -
Computational Overheads of SVD:
While our method avoids unbounded parameter growth, repeated SVD computations introduce overhead. Efficiency may be improved by restricting SVD to a subset of layers (e.g., attention projections) or using faster approximations. -
Dynamic Capacity Allocation for Long Task Streams:
Our current method pre-allocates subspace budgets, which can limit scalability over long task sequences. A promising future direction is to explore flexible or adaptive subspace management strategies that adjust capacity based on task complexity or model usage.
Conclusion: Toward Truly Lifelong Learning Models
Catastrophic forgetting has long stood as a formidable barrier to deploying large language models in continuously evolving real-world scenarios. Existing solutions—replay buffers, parameter-efficient methods like LoRA, and complex model merging—have significant practical drawbacks.
Our novel solution, Adaptive SVD—Sculpting Subspaces—addresses these limitations head-on by intelligently updating models in unused parameter subspaces while carefully preserving crucial knowledge. Our approach delivers impressive results:
- ✅ State-of-the-art accuracy across diverse benchmarks.
- ✅ Significant reduction in forgetting.
- ✅ Stable general linguistic capabilities, instruction-following, and safety.
Ultimately, our method bridges theory and practice, enabling enterprises to deploy truly adaptive, continuously learning models at scale. It’s a crucial advance towards practical, lifelong-learning systems that seamlessly evolve in step with our ever-changing world. We believe this is just the beginning. This approach brings us one significant step closer to genuinely adaptive AI, ready to meet the complex and ever-changing demands of tomorrow.
🔗 Resources and Follow Us
Thanks for joining us on this journey through our paper and approach. We’re excited about what’s next, and we hope you are too!
- 💻 Code Repository: https://github.com/Red-Hat-AI-Innovation-Team/orthogonal-subspace-learning
- 📢 Stay Updated: Follow our latest research and updates at https://ai-innovation.team
📚 References
- Brown, T. et al. (2020). Language Models are Few-Shot Learners.
- Chowdhery, A. et al. (2022). PaLM: Scaling Language Modeling with Pathways.
- Hartford, J. et al. (2024). Spectrum: Targeted Training on Signal to Noise Ratio.
- Houlsby, N. et al. (2019). Parameter-Efficient Transfer Learning for NLP.
- Hu, E. J. et al. (2022). LoRA: Low-Rank Adaptation of Large Language Models.
- Kirkpatrick, J. et al. (2017). Overcoming Catastrophic Forgetting in Neural Networks.
- Liang, Z. et al. (2024). InfLoRA: Interference-free Low-Rank Adaptation for Continual Learning.
- Sharma, U. et al. (2023). LASER: The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction.
- Touvron, H. et al. (2023). LLaMA: Open and Efficient Foundation Language Models.
- Wang, J. et al. (2024). O-LoRA: Orthogonal Subspace Learning for Language Model Continual Learning.
- Wang, Y. et al. (2023). TRACE: A Comprehensive Benchmark for Continual Learning in Large Language Models.
- Zenke, F. et al. (2017). Continual Learning through Synaptic Intelligence.
- Zhang, X. et al. (2015). Character-level Convolutional Networks for Text Classification.
{kind=link}