

Get started with language model post-training using Training Hub
Introducing Training Hub: An open source, algorithm-centered library for LLM training.
Introducing Training Hub: An open source, algorithm-centered library for LLM training.
Post-training adapts language models for specific, safe, and practical uses. This overview highlights key methods and the open source training_hub library.

Customize reasoning models with synthetic data generation for enterprise deployment. Learn techniques from Red Hat's AI Innovation Team.

Discover inference-time scaling techniques that improve AI quality and reliability for enterprise applications beyond just speed optimization.

Introducing Async-GRPO - an open-source library for scalable reinforcement learning with 42% efficiency gains over VERL and 11x over TRL for GRPO training.
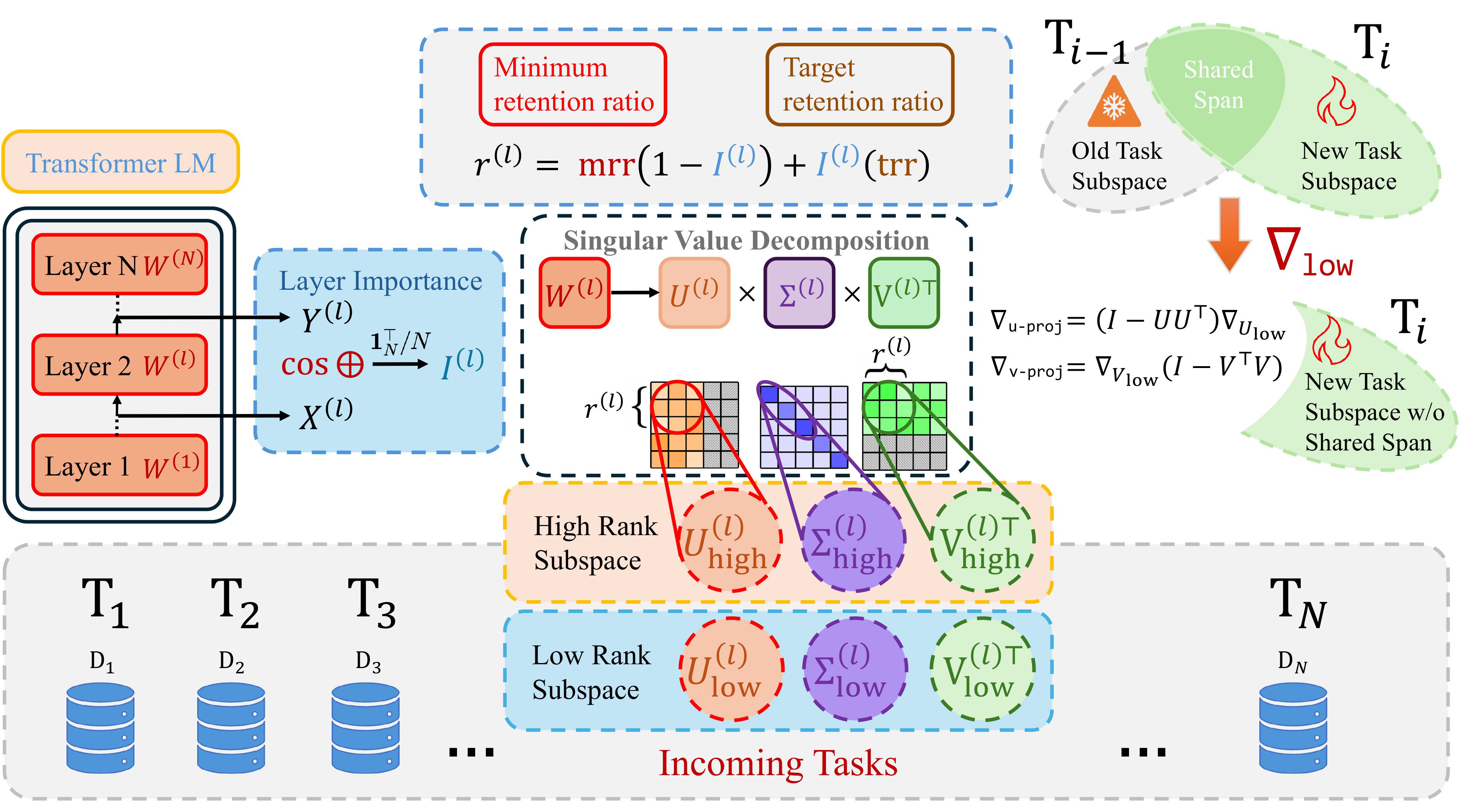
Learn how our adaptive SVD method enables continual learning in LLMs with near-zero catastrophic forgetting, achieving 7% higher accuracy than baselines.
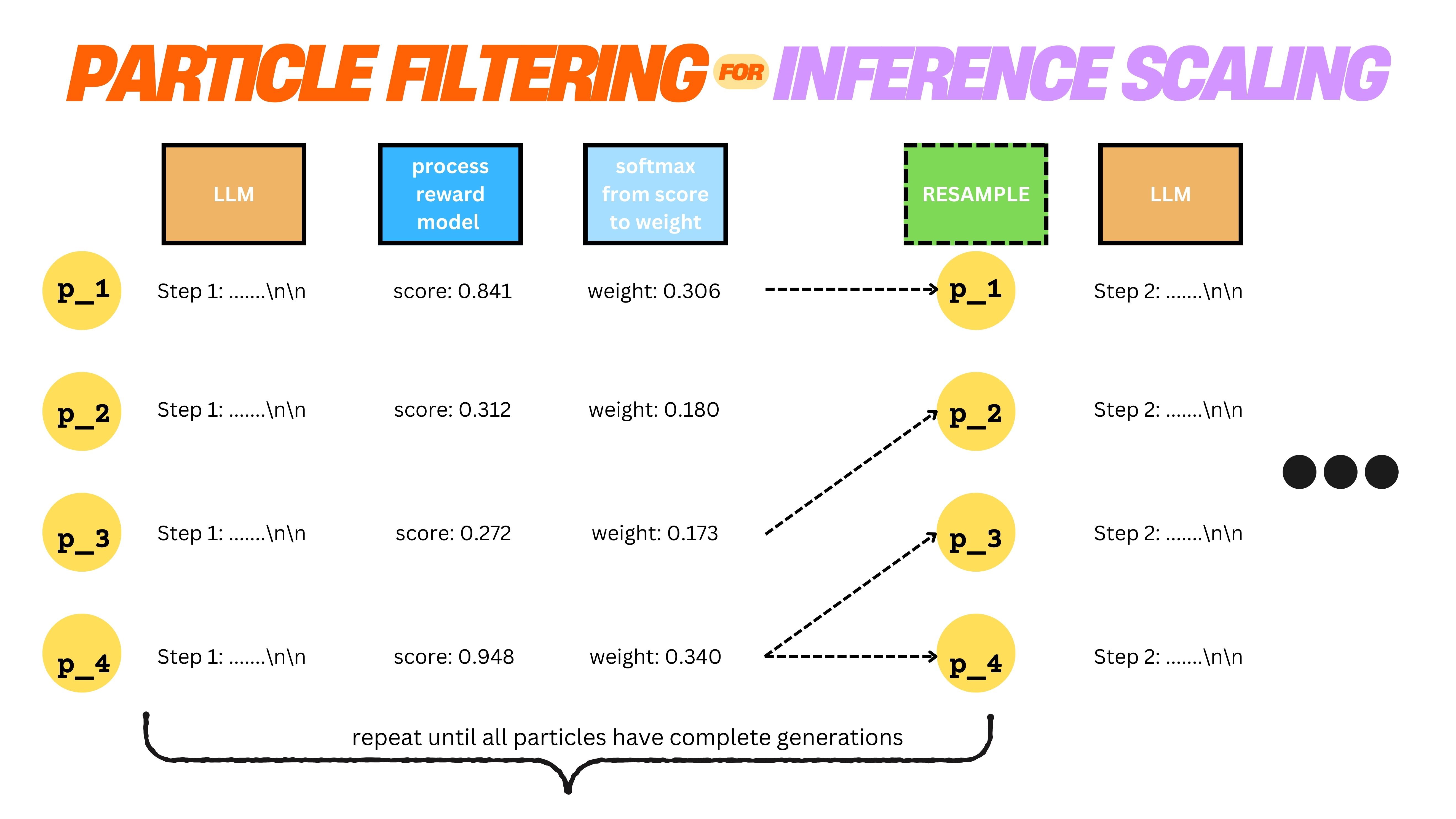
Understanding the distinction between reasoning and inference-time scaling in LLMs - insights from our R1 reproduction experiments.
Second update on R1 reasoning research - new results on training small LLMs with synthetic reasoning data and particle filtering methods.
First update on R1-like reasoning experiments - Granite models show significant gains with particle filtering and new data quality experiments.