



SpecBench: Turning Intent into Specifications
SpecBench benchmarks how well AI coding agents collaborate with users to turn vague ideas into structured specifications, and introduces Buddy, an agent that drafts better specs with fewer questions.
A collective of researchers and engineers from Red Hat & IBM building LLM toolkits you can use today.


Inference-time scaling for LLMs.


Synthetic data generation pipelines


Post training algorithms for LLMs


Asynchronous GRPO for scalable reinforcement learning.


A method for skipping redundant attention blocks in language models


Efficient training library for large language models up to 70B parameters on a single node.


Adaptive SVD-based continual learning method for LLMs.


Inference-time scaling with particle filtering.


State-of-the-art reward models for preference data generation and acceptance criteria.


KV cache quantization for scaling inference time


Efficient messages-format SFT library for language models
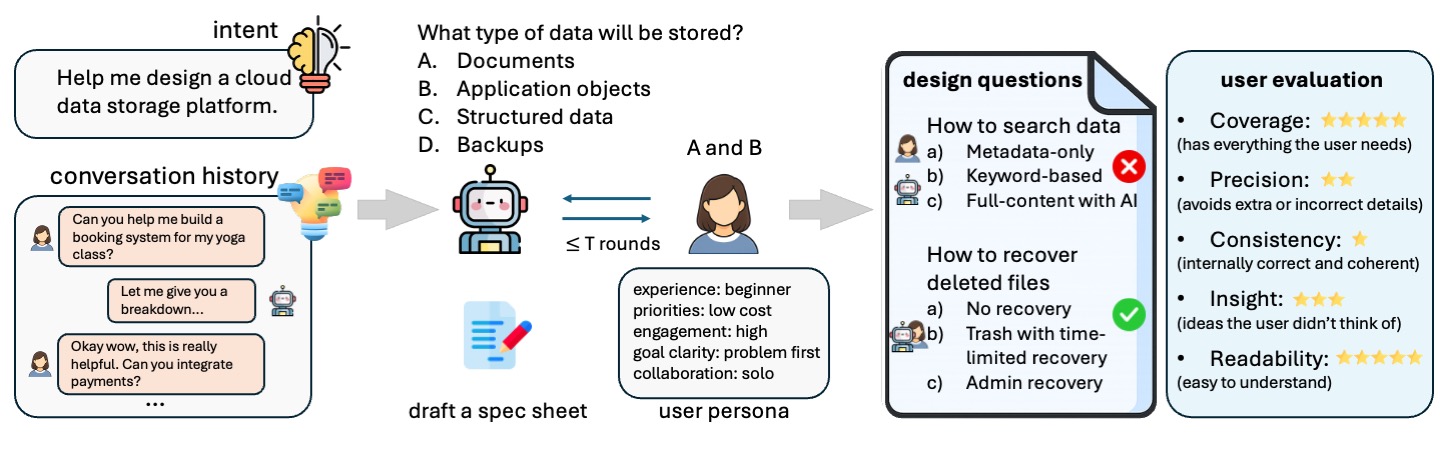
SpecBench benchmarks how well AI coding agents collaborate with users to turn vague ideas into structured specifications, and introduces Buddy, an agent that drafts better specs with fewer questions.
Training Hub v0.4.0 adds LoRA and QLoRA fine-tuning powered by Unsloth, enabling fast, cost-effective model adaptation with roughly 70% less VRAM than full fine-tuning.
A four-step pathway for scaling LLM fine-tuning from local experimentation to production deployment using Training Hub, OpenShift AI, Kubeflow Trainer, and AI pipelines.
📹 Adaptive Soft-Thresholding for Hardware-Aligned Model Compression
👤 Speaker: Ayoub Ghriss
July 10, 2026
📹 Rounding to Remember: How Weight-Storage Precision Controls Catastrophic Forgetting
👤 Speaker: Oleg Silkin
June 26, 2026
📹 A Closer Look at RLVR Through the Lens of Reasoning Strategies
👤 Speaker: Eshwar Sivaramakrishnan
June 12, 2026