



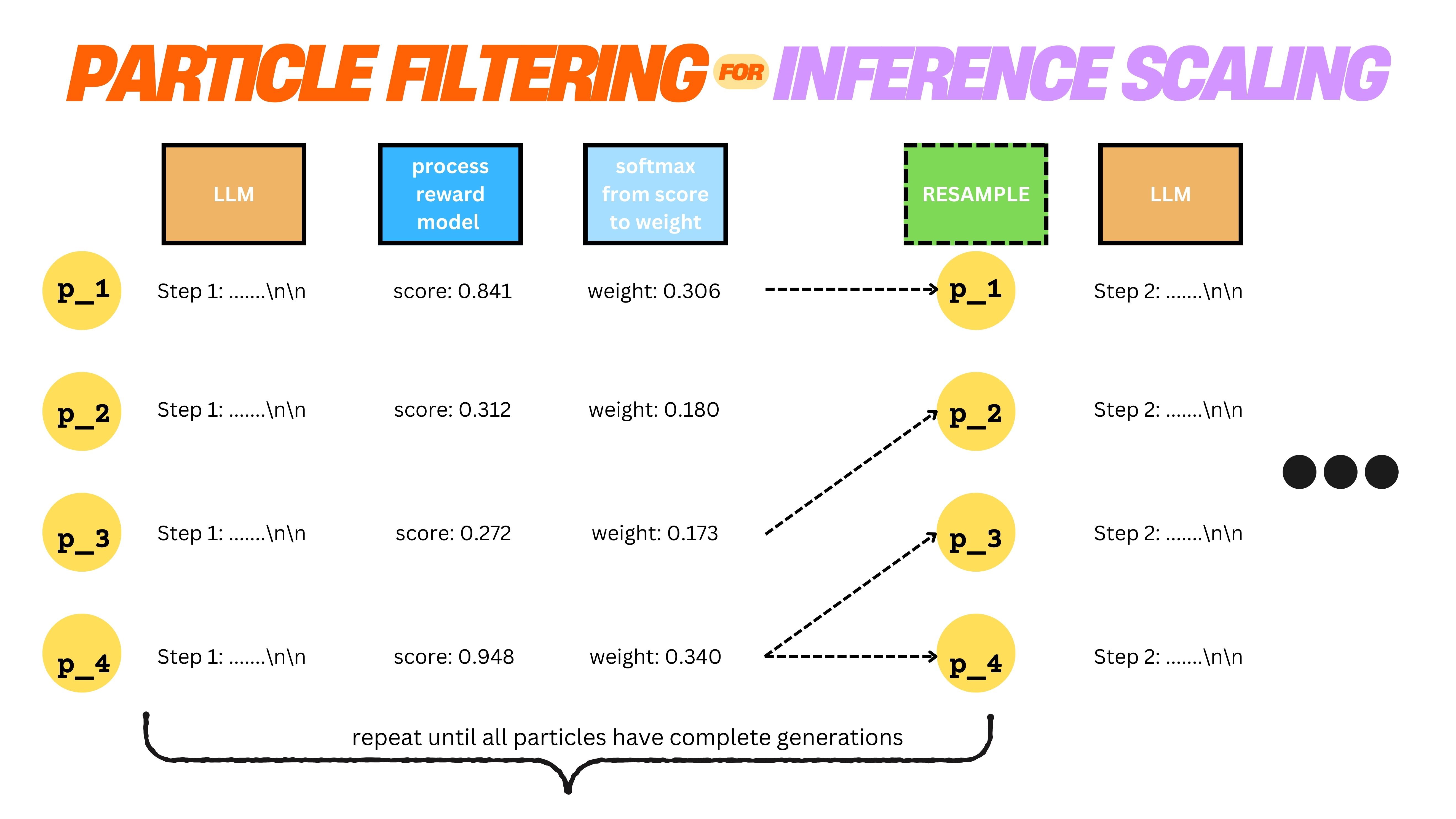
Update 3 - On Reasoning vs Inference-time scaling - Lessons on Reproducing R1-like Reasoning in Small LLMs without using DeepSeek-R1-Zero (or its derivatives)
Understanding the distinction between reasoning and inference-time scaling in LLMs - insights from our R1 reproduction experiments.