



Lessons on Reproducing R1-like Reasoning in Small LLMs without using DeepSeek-R1-Zero (or its derivatives)
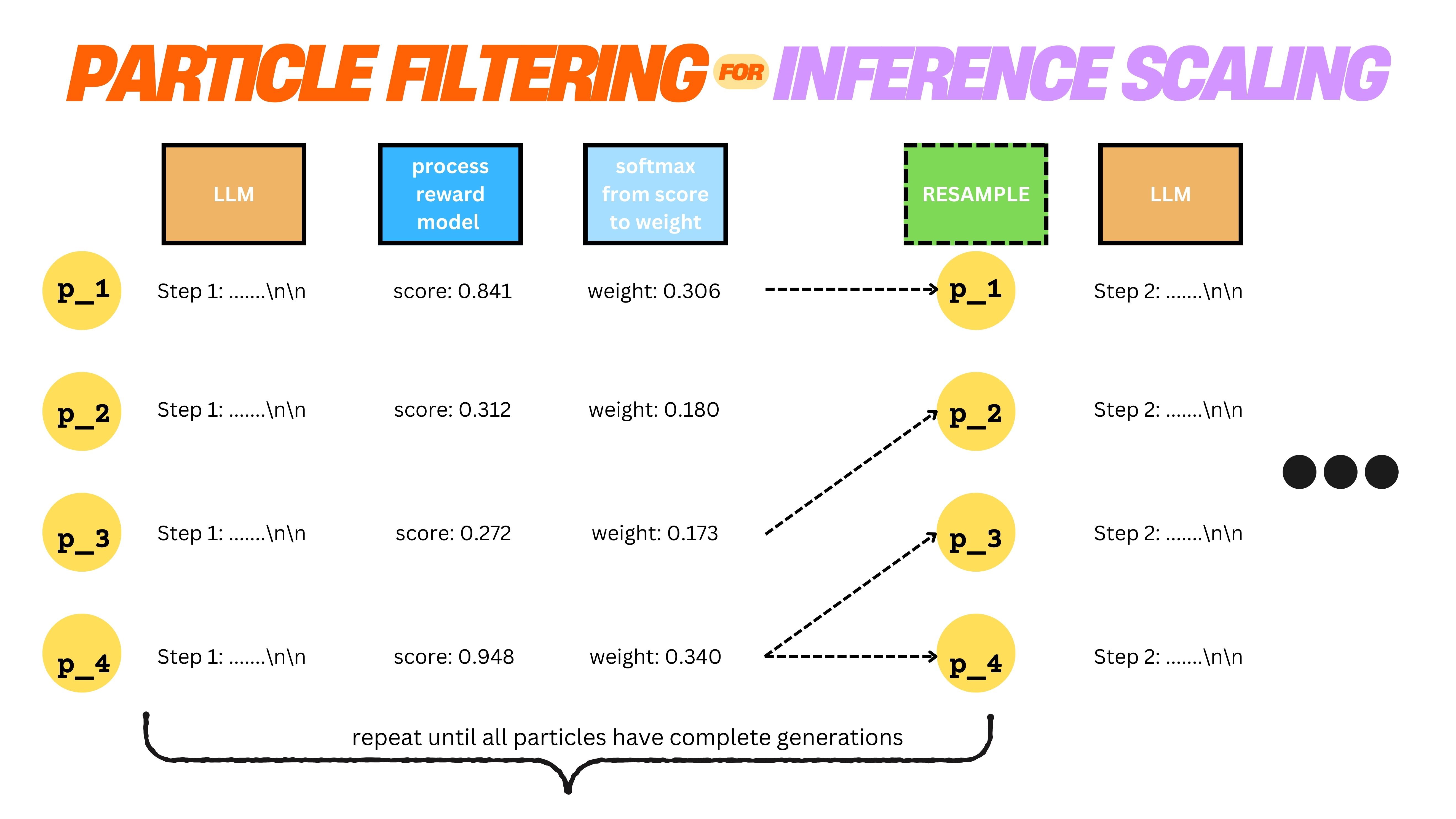
Learn how to reproduce R1-like reasoning in small LLMs using particle filtering, synthetic data, and GRPO - achieving GPT-4o accuracy with only 4 rollouts.